Data
Data is/are the
facts of the World. For example,
take yourself. You may be 5ft tall, have brown hair and blue eyes. All
of this is “data”. You have brown hair whether this is written down
somewhere or not.
In many ways, data can be thought of as a
description of the World. We can perceive this data with our senses, and then the brain can process this.
Human beings have used data as long as we’ve existed to form knowledge of the world.
Information
Information allows us to expand our knowledge beyond the range of our senses. We can
capture data in information, then move it about so that other people can access it at different times.
Here is a simple analogy for you.
If I take a picture of you,
the photograph is information. But what you look like is data.
I can move the photo of you around, send it to other people via e-mail etc. However, I’m not actually moving
you around – or
what you look like.
I’m simply allowing other people who can’t directly see you from where
they are to know what you look like. If I lose or destroy the photo,
this doesn’t change how you look.
So, in the case of the lost tax records, the CDs were information.
The information was lost, but
the data wasn’t. Mrs Jones still lives at 14 Whitewater road, and she was still born on 15th August 1971.
Some differences between data and information:
-
Data is used as input for the computer system. Information is the output of data.
-
Data is unprocessed facts figures. Information is processed data.
-
Data doesn’t depend on Information. Information depends on data.
-
Data is not specific. Information is specific.
-
Data is a single unit. A group of data which carries news and meaning is called Information.
-
Data doesn’t carry a meaning. Information must carry a logical meaning.
-
Data is the raw material. Information is the product.
Traditional File Processing System
File processing systems was an early attempt to computerize the manual filing system that we are all familiar with. A file system is a method for storing and organizing computer files and the data they contain to make it easy to find and access them. File systems may use a storage device such as a hard disk or CD-ROM and involve maintaining the physical location of the files.
In our own home, we probably have some sort of filing system, which contains receipts, guarantees, invoices, bank statements, and such like. When we need to look something up, we go to the filing system and search through the system starting from the first entry until we find what we want. Alternatively, we may have an indexing system that helps to locate what we want more quickly. For example we may have divisions in the filing system or separate folders for different types of item that are in some way logically related.
The manual filing system works well when the number of items to be stored is small. It even works quite adequately when there are large numbers of items and we have only to store and retrieve them. However, the manual filing system breaks down when we have to cross-reference or process the information in the files. For example, a typical real estate agent's office might have a separate file for each property for sale or rent, each potential buyer and renter, and each member of staff.
Clearly the manual system is inadequate for this' type of work. The file based system was developed in response to the needs of industry for more efficient data access. In early processing systems, an organization's information was stored as groups of records in separate files.
In the traditional approach, we used to store information in flat files which are maintained by the file system under the operating system's control. Here, flat files are files containing records having no structured relationship among them. The file handling which we learn under C/C ++ is the example of file processing system.
Characteristics of File Processing System
Here is the list of some important characteristics of file processing system:
• It is a group of files storing data of an organization.
• Each file is independent from one another.
• Each file is called a flat file.
• Each file contained and processed information for one specific function, such as accounting or inventory.
• Files are designed by using programs written in programming languages such as COBOL, C, C++.
•
The physical implementation and access procedures are written into
database application; therefore, physical changes resulted in intensive
rework on the part of the programmer.
•
As systems became more complex, file processing systems offered little
flexibility, presented many limitations, and were difficult to maintain.
Limitations of the File Processing System I File-Based Approach
There are following problems associated with the File Based Approach:
1. Separated and Isolated Data:
To make a decision, a user might need data from two separate files.
First, the files were evaluated by analysts and programmers to determine
the specific data required from each file and the relationships between
the data and then applications could be written in a programming
language to process and extract the needed data. Imagine the work
involved if data from several files was needed.
2. Duplication of data:
Often the same information is stored in more than one file.
Uncontrolled duplication of data is not required for several reasons,
such as:
• Duplication is wasteful. It costs time and money to enter the data more than once
• It takes up additional storage space, again with associated costs.
•
Duplication can lead to loss of data integrity; in other words the data
is no longer consistent. For example, consider the duplication of data
between the Payroll and Personnel departments. If a member of staff
moves to new house and the change of address is communicated only to
Personnel and not to Payroll, the person's pay slip will be sent to the
wrong address. A more serious problem occurs if an employee is promoted
with an associated increase in salary. Again, the change is notified to
Personnel but the change does not filter through to Payroll. Now, the
employee is receiving the wrong salary. When this error is detected, it
will take time and effort to resolve. Both these examples, illustrate
inconsistencies that may result from the duplication of data. As there
is no automatic way for Personnel to update the data in the Payroll
files, it is difficult to foresee such inconsistencies arising. Even if
Payroll is notified of the changes, it is possible that the data will be
entered incorrectly.
3. Data Dependence:
In file processing systems, files and records were described by
specific physical formats that were coded into the application program
by programmers. If the format of a certain record was changed, the code
in each file containing that format must be updated. Furthermore,
instructions for data storage and access were written into the
application's code. Therefore, .changes in storage structure or access
methods could greatly affect the processing or results of an
application.
In
other words, in file based approach application programs are data
dependent. It means that, with the change in the physical representation
(how the data is physically represented in disk) or access technique
(how it is physically accessed) of data, application programs are also
affected and needs modification. In other words application programs are
dependent on the how the data is physically stored and accessed.
If
for example, if the physical format of the master/transaction file is
changed, by making he modification in the delimiter of the field or
record, it necessitates that the application programs which depend on it
must be modified.
Let
us consider a student file, where information of students is stored in
text file and each field is separated by blank space as shown below:
I Rahat 35 Thapar
Now, if the delimiter of the field changes from blank space to semicolon as shown below:
1; Rahat; 35; Thapar
Then,
the application programs using this file must be modified, because now
it will token the field on semicolon; but earlier it was blank space.
4. Difficulty in representing data from the user's view:
To create useful applications for the user, often data from various
files must be combined. In file processing it was difficult to determine
relationships between isolated data in order to meet user requirements.
5. Data Inflexibility:
Program-data interdependency and data isolation, limited the
flexibility of file processing systems in providing users with ad-hoc
information requests
6. Incompatible file formats:
As the structure of files is embedded in the application programs, the
structures are dependent on the application programming language. For
example, the structure of a file generated by a COBOL program may be
different from the structure of a file generated by a 'C' program. The
direct incompatibility of such files makes them difficult to process
jointly.
7. Data Security.
The security of data is low in file based system because, the data is
maintained in the flat file(s) is easily accessible. For Example:
Consider the Banking System. The Customer Transaction file has details
about the total available balance of all customers. A Customer wants
information about his account balance. In a file system it is difficult
to give the Customer access to only his data in the· file. Thus
enforcing security constraints for the entire file or for certain data
items are difficult.
8. Transactional Problems.
The File based system approach does not satisfy transaction properties
like Atomicity, Consistency, Isolation and Durability properties
commonly known as ACID properties.
For
example: Suppose, in a banking system, a transaction that transfers Rs.
1000 from account A to account B with initial values' of A and B being
Rs. 5000 and Rs. 10000 respectively. If a system crash occurred after
the withdrawal of Rs. 1000 from account A, but before depositing of
amount in account B, it will result an inconsistent state of the system.
It means that the transactions should not execute partially but wholly.
This concept is known as Atomicity of a transaction (either 0% or 100%
of transaction). It is difficult to achieve this property in a file
based system.
9. Concurrency problems.
When multiple users access the same piece of data at same interval of
time then it is called as concurrency of the system. When two or more
users read the data simultaneously there is ll( problem, but when they
like to update a file simultaneously, it may result in a problem.
10. Poor data modeling of real world.
The file based system is not able to represent the complex data and
interfile relationships, which results poor data modeling properties.
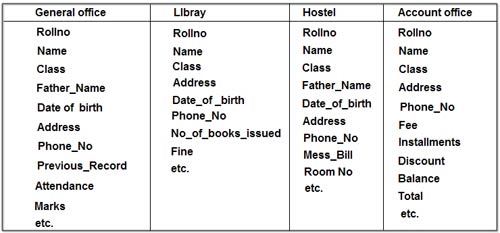
Case Study
In
case of college database, there may be the number of applications like
General Office, Library, Account Office, Hostel etc. Each of these
applications may maintain the following information into own private
file applications in case of file management system:
It
is clear from the above file systems, that there are some common data
items of the student which has to be mentioned in each application, like
Rollno, Name, Class, Father_Name, Address, Phone_No, Date_of_birth etc.
which are stored repeatedly in file system in each application. It will
cause the problem of redundancy which results in wastage of storage
space and difficulty in maintenance. So, we should look for a solution
to these types of redundancies. The database approach discussed below
will help us to provide the solution for above problems.